There are many ways in which you can make use of the Inverse Moving Average.
One of the most important of these is in connection with the half-span average concept. Let's see how it can work for you.
Direct your attention to Figure VI-8.
Here is a weekly plot of Alloys Unlimited over the entire time period covered by illustrations VI-1 through VI-7.
This time, instead of using a 10-week average, an 11-week one is shown. With the number of elements of the average being "odd," each average datum directly corresponds (in time) to a weekly price datum instead of falling in midweek (as for the ten-week one).
In this way subtraction can be accomplished directly without need for interpolation.
As formed, each Moving Average is subtracted from the corresponding mean weekly price of the stock The results could be plotted as points about a "zero" base line, either by themselves or connected by straight lines.
However, the process of erecting vertical lines from zero to the value of the difference (as in Figure VI-8) seems to provide the eye with more information. What can we make of this plot ?
First of all,the dominant cyclic component just shorter in duration than the trading cycle is now clearly evident.
Counting weeks (low-to-low and high-to-high) and averaging gives a nominal duration of 12.7 weeks, with a "spread" from 10 to 16.
The correlation with an expected component of the price-motion model is obvious.
Secondly, it is seen that the magnitude of this cycle averages 7 points peak-to-peak ( +/- 3.50 points).
It is seen that the inverse average provides cycle magnitude directly, without necessity for, and without the error inherent in, the construction of envelopes!
Thirdly, we note that a simple process of subtraction converts a half-span average (which is vitally useful on its own) into that specific inverse average which is most capable of identifying the component of duration just less than that of the trading cycle.
As seen in previous chapters, identification of this component is an essential part of the process of setting up trailing loss levels and sell signals in general. And, you will normally have already computed the half-span average anyway !
Now. How does all this aid transaction timing?
Return to Figure VI-6 and VI-7.
In the discussions regarding these figures it is noted that the half-span average had put us in the stock short at 51 to 52. But, prices seemed to refuse to go down -oscillating instead from 44 to 51 for 9 weeks.
The half-span analysis assured us the stock was headed for 40.625. Does the inverse half-span confirm this conclusion ?
In Figure VI-8, the inverse half-span average is 2 weeks away from a low of the2.7-week cycle.
The stock price is an additional 5 weeks along (due to the lag of the average). So, we're now 7 weeks along on a component (next shorter in duration than the trading cycle) which averages 12.7 weeks, and varies from 10 to 16 weeks.
We expect the next significant low of this cycle in a time zone 3 to 9 weeks from now.
In addition, the 21.7-week (average) duration trading cycle (which varies from 20 to 23 weeks in length) is now 19 weeks along from a low.
We expect the next significant low of this cycle in a time zone 1 to 4 weeks from now.
With both of these important cycles due to low out in the same general time period, we know the stock still has more to go on the downside.
In fact, taking 6/13 of 7 points, we expect about 3.7 points more on the downside from the 12.7-week cycle alone.
An additional 3/22 of 14 or 1.9 points remains in the 2 1.7-week cycle.
The present price is 45 which, less 4.6, leaves 40.50 as a low-out estimate.
We conclude that the stock will reach approximately 40.50 within 1 to 9 weeks.
This estimate compares almost identically with that obtained using the halfspan average alone (40.625 in 3 weeks )- yet was obtained using information the halfspan average "threw away"!
With this additional reassurance, we do not hesitate to remain in our short Position - and the stock proceeded to bottom out at 41 the next week, nicely within our tolerance zone !
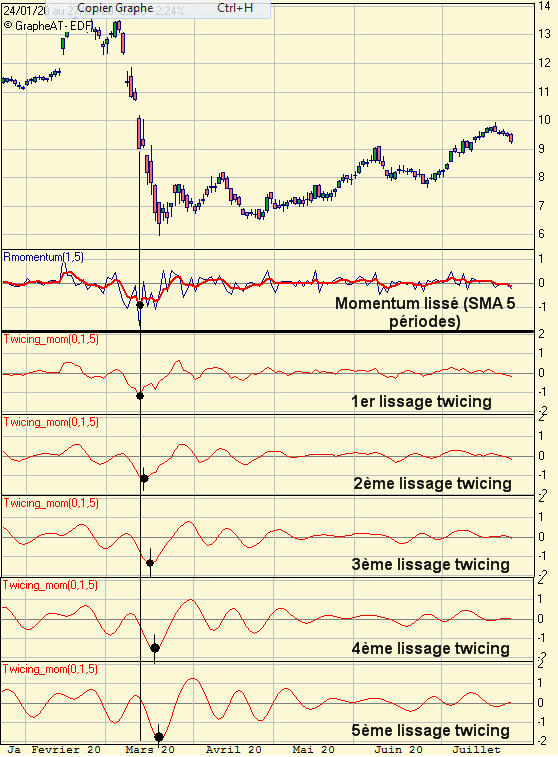
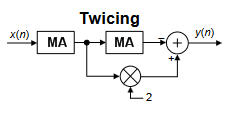
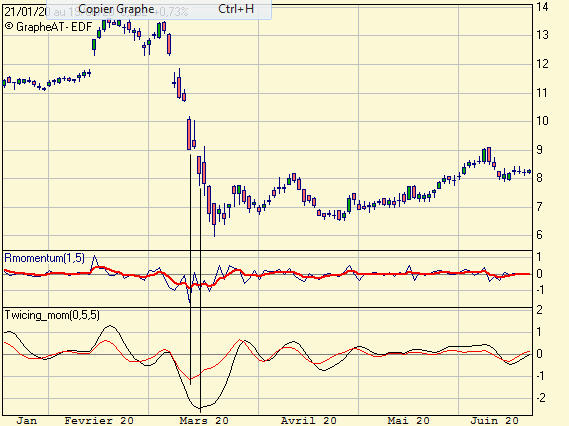
 Comme le résidu est sensiblement de moyenne nulle, certaines techniques difficilement applicables avec le trend deviennent possibles, comme par exemple la transformée de Fourier.
Comme le résidu est sensiblement de moyenne nulle, certaines techniques difficilement applicables avec le trend deviennent possibles, comme par exemple la transformée de Fourier.")







Laisser un commentaire: